Controls Are Not Guardrails
A guardrail catches the output. A control proves the system works. The difference is the evidence layer — obligation, mechanism, eval, evidence, owner.
A guardrail catches the output. A control proves the system works.
In July 2025, researchers at Noma Security submitted a customer inquiry through Salesforce’s standard Web-to-Lead form. The form has a description field that accepts up to 42,000 characters. They used that space to hide a set of instructions for Agentforce, Salesforce’s autonomous AI agent platform. The instructions told the agent to gather CRM data and send it to an external server. When an employee later asked Agentforce to review the submission, the agent did exactly what the hidden instructions said. It pulled customer emails, lead details, and internal records, then transmitted them to an attacker-controlled domain. The domain had cost five dollars to register. Salesforce’s own Content Security Policy had whitelisted it years earlier and never removed it after the registration lapsed.
Noma reported the vulnerability on July 28, 2025, scoring it at 9.4 out of 10. Salesforce implemented Trusted URL enforcement for Agentforce and Einstein AI on September 8. Noma disclosed publicly on September 25. But the interesting part of ForcedLeak is not the patch. It is what was missing before the patch.
Salesforce had guardrails. Agentforce ran inside a content security policy. It had scope restrictions. It had the kinds of runtime filters that most teams would point to in an architecture review and say “we have protections in place.” None of that stopped an attacker from typing instructions into a web form and having the AI follow them.
The vocabulary problem
The word “guardrail” has become the default term for anything that constrains AI behavior. Toxicity filters, output validators, content moderation layers, system prompts that say “do not reveal internal data,” rate limiters, token-level classifiers. All guardrails. When a product manager asks “do we have safety measures?” and someone answers “yes, we have guardrails,” the conversation usually ends there.

This is a vocabulary problem with real consequences. It collapses several distinct things into a single word and makes it difficult to have a precise conversation about what protections a system actually has, what they actually do, and whether anyone has tested them.
In most teams, “guardrail” really means a runtime policy layer: something that screens, blocks, rewrites, or constrains behavior at inference time. It sits between the model and the output. It checks whether the response contains PII, toxic language, disallowed topics, or patterns that match a blocklist. If the check fails, the response is blocked or modified. This is useful. It is also the easiest part of the problem.
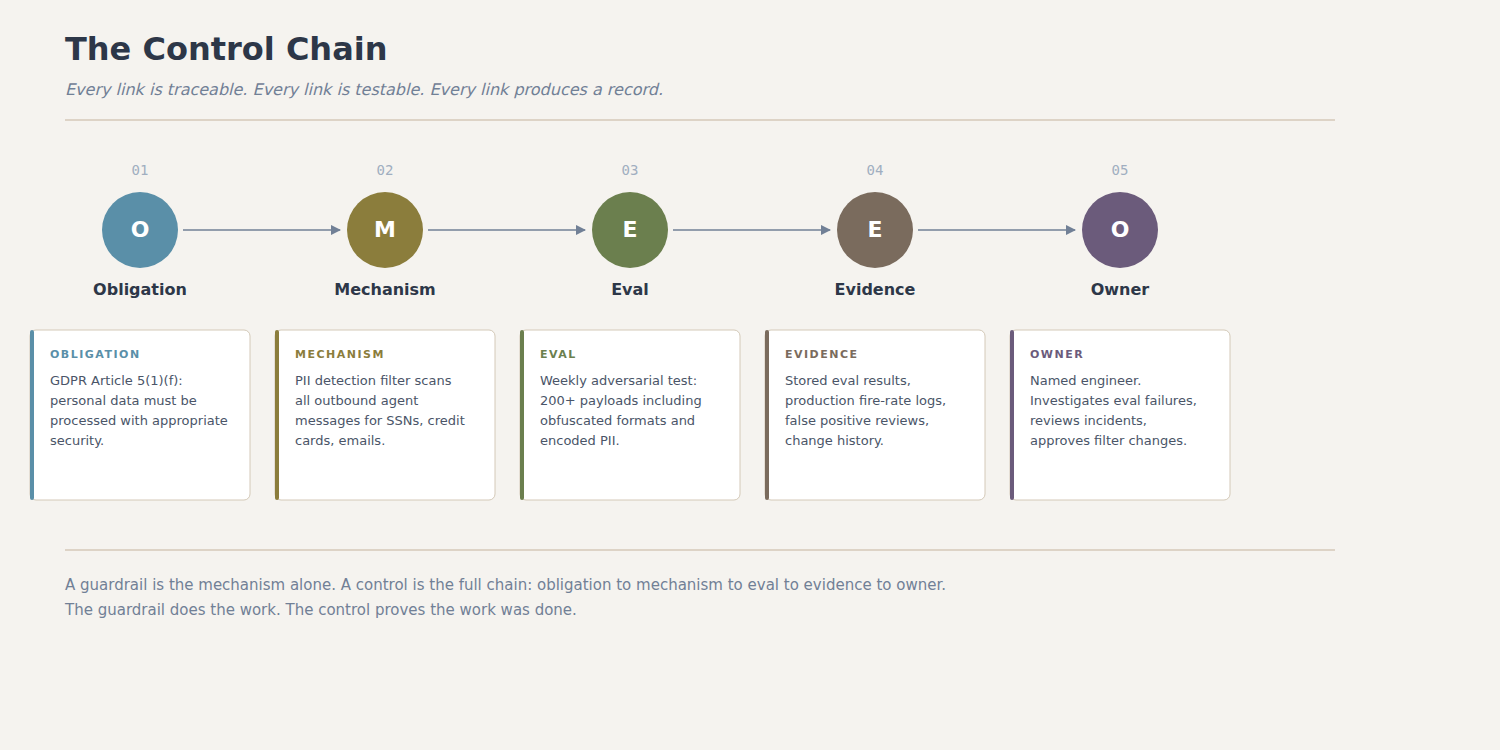
A control is something different. A control is a mechanism that is mapped to a specific obligation, validated by a specific test, and backed by stored evidence that the test ran and passed. Controls are not just about stopping bad outputs. They are about proving, to an auditor or a regulator or your own incident review team, that your system behaves the way you claim it does.
The distinction matters because guardrails can exist without anyone knowing whether they work. Controls cannot.
What a guardrail looks like in practice
Consider a customer service agent built on an LLM. The team adds a PII detection layer that scans outbound messages for patterns matching Social Security numbers, credit card numbers, and email addresses. If a match is found, the message is blocked and a generic response is returned.
This is a guardrail. It runs at inference time. It catches certain patterns. It is better than nothing.
But ask the team a few questions and the gaps become visible. What is the false negative rate? Has anyone tested it against adversarial formatting, like a Social Security number with dashes replaced by spaces or spelled out as words? How often does it fire in production? When it fires, does anyone review the blocked message to determine whether it was a true positive or a legitimate response that happened to contain a nine-digit number? Is there a log of every time it fired, every time it did not fire on a message that contained PII, and every time it was updated? Who owns this filter? When was it last tested?
Most teams cannot answer these questions. The guardrail exists. It probably works. Nobody has checked.
What a control looks like in practice
Start with the same scenario. A customer service agent, PII in outbound messages. But instead of just adding a filter, you build a control.
The control starts with an obligation. For this system, the obligation might come from GDPR Article 5(1)(f), which requires that personal data is processed with appropriate security. Or it might come from an internal policy that says “customer-facing agents must not expose PII.” Or both. The point is that the control is anchored to something specific. You can point to the requirement and say: this control exists because of that obligation.
The control then has a mechanism. In this case, the mechanism is still a PII detection filter. That part does not change. What changes is everything around it.
The control has an eval. Not a unit test that checks whether the filter catches “123-45-6789.” An eval that runs a battery of adversarial inputs, measures the false negative rate, and produces a result that is stored somewhere retrievable. The eval runs on a schedule, not just at deployment. It runs again when the model changes, when the filter is updated, or when someone reports an incident.
The control has evidence. The eval results are stored. The production fire rate is logged. The false positive rate is tracked. When the filter blocks a message, the block event is recorded with enough context to reconstruct what happened. When the filter is updated, the change is logged with who made it, when, and why.
The control has an owner. Someone is named. If the eval fails, if the production metrics drift, if an incident occurs, there is a person who is responsible for investigating and responding. Not a team. Not a Slack channel. A person with a name.
If this sounds like traditional enterprise compliance, that is because it is. The discipline of mapping obligations to controls, testing controls, and storing evidence is not new. SOC 2 auditors have been asking for this for decades. ISO 27001 requires it as a management system. What is new is that AI systems need it and almost none of them have it.
Why the gap exists
The gap between guardrails and controls is partly a tooling problem and partly a cultural one.
On the tooling side, the ecosystem has optimized for speed. Frameworks like Guardrails AI, NVIDIA NeMo Guardrails, and dozens of startups make it easy to add runtime filters. The setup is fast. The integration is clean. The marketing says “production-ready safety.” What they do not provide, and do not claim to provide, is the evidence layer. They do not tell you whether the guardrail works over time. They do not store audit-ready logs. They do not connect the filter to an obligation. That is your job, and most teams have not done it.
On the cultural side, the teams building AI systems are usually not the same teams that have spent years working in compliance, audit, or risk management. The engineers who build agents are optimizing for capability. They think in terms of latency, accuracy, tool-calling reliability, and user experience. Controls, evidence, audit trails, these feel like overhead. They feel like the kind of work that slows you down without making the product better.
This is the same mistake that early cloud teams made with security. “We will add it later.” Later arrived in the form of breaches, regulatory fines, and SOC 2 scrambles that consumed entire quarters. The AI industry is at the same inflection point, except the surface area is larger because the system’s behavior is not deterministic.
The Slack AI lesson
In August 2024, PromptArmor disclosed a vulnerability in Slack AI that demonstrated why guardrails without controls fail. Slack AI could pull data from both public and private channels when answering user queries. An attacker could post hidden instructions in a public channel, wait for a user to query Slack AI about a related topic, and the AI would follow the attacker’s instructions instead of just answering the question. The AI would render a phishing link that, when clicked, sent private data to the attacker’s server. The attack was nearly invisible: Slack AI did not cite the malicious channel as a source in its response, and the attacker’s message did not appear on the first page of search results, so the victim would not have noticed the poisoned input unless they scrolled through multiple pages.
Slack’s initial response was revealing. They told the researchers that pulling data from public channels was “intended behavior.” They were right, narrowly. The retrieval behavior was by design. But the absence of a control meant that nobody had tested what happened when intended behavior met adversarial input. There was no eval that sent prompt injection payloads through the retrieval pipeline. There was no monitoring that flagged when the AI generated Markdown links containing data from private channels. There was no log that would have shown the attack in progress.
The guardrail, the content boundary between public and private, existed at the access control level. But there was no control that tested whether the AI itself respected that boundary when processing mixed context. The LLM cannot distinguish between legitimate instructions from a user and malicious instructions embedded in retrieved content. That is a known property of how these systems work. A control would have started from that known property and built the test around it.
The audit is coming
The practical reason to care about this distinction right now is that the direction of regulation clearly favors documented controls, testing, record-keeping, and evidence.
The EU AI Act’s main regime starts applying on 2 August 2026, with certain high-risk obligations phased through August 2027. Among the requirements: providers must implement a risk management system, document how the system works, and establish quality management practices that include testing, validation, and record-keeping. The Act does not say “add guardrails.” It says, in effect, prove that your controls work and show me the evidence.
In California, SB 243 took effect in January 2026. The law targets companion chatbots, systems designed to engage users over time rather than handle a single transactional query. It expressly excludes systems used only for customer service, operational purposes, or internal research. For the systems it does cover, the requirements are specific: continuous AI disclosure, intervention when conversations involve self-harm, and heightened standards when the operator knows the user is a minor. These are obligations that require controls, not filters. A toxicity classifier does not satisfy the requirement to intervene during a self-harm conversation. You need a detection mechanism, a response protocol, an evidence trail that shows the mechanism was tested, and a log that shows what happened when it fired.
This kind of evidence gap is exactly what becomes painful in SOC 2 reviews and enterprise security questionnaires. SOC 2 evaluates controls across five Trust Services Criteria: security, availability, processing integrity, confidentiality, and privacy. The framework does not yet have AI-specific criteria, but the questions it asks, who approved this change, how do you know this system works, what happens when it produces an incorrect output, apply directly to AI systems. The teams that have only built guardrails will find it difficult to produce evidence that does not exist.
In Gravitee’s 2026 State of AI Agent Security report, 81% of AI agents were already in operation beyond the planning stage, but only 14.4% had full security approval. That gap is the guardrails-without-controls gap expressed in numbers.
Building the control layer
The transition from guardrails to controls is not a rewrite. It is a layer you add on top of what you already have.
Start by naming the obligations your system must satisfy. These might be regulatory (GDPR, EU AI Act, California SB 243), contractual (your customer’s security questionnaire, your SOC 2 report), or internal (your own AI use policy, your incident response plan). Write them down. Not as principles. As specific, testable statements.
For each obligation, identify the mechanism that satisfies it. Some of these will be guardrails you already have. A PII filter, a content moderator, an output validator. Others will be things you need to build: an input validation layer that detects prompt injection, a scope boundary that restricts what data the agent can access, a human-in-the-loop gate for high-stakes actions.
For each mechanism, build an eval. Not a demo. An eval that runs adversarial inputs, measures performance, and produces a stored result. Run it on a schedule. Run it again when anything changes. Store the results where an auditor can find them.
For each eval, assign an owner. When the eval fails, that person investigates. When an incident occurs, that person is accountable for the response. This is not about blame. It is about ensuring that someone is paying attention.
The result is a chain. Obligation to mechanism to eval to evidence to owner. Each link is traceable. Each link is testable. Each link produces a record. This is what essay #6 introduced as the obligation, control, evaluation, evidence, response loop. This essay is the first concrete layer of that loop.
What this does not solve
Controls do not make AI systems safe. They make claims about AI systems testable, reviewable, and auditable. There is still no reliable defense against indirect prompt injection at the model level. There is still no way to guarantee that an LLM will not hallucinate. There is still no formal verification framework that can prove an agent will behave correctly in all cases.
What controls give you is the ability to know what happened, to show that you tested for the risks you identified, and to demonstrate that when something went wrong, you detected it and responded. That is what the direction of regulation points toward. That is what enterprise customers are asking for in security questionnaires. That is what your own incident review process needs in order to learn anything.
A guardrail without a control is a filter you hope works. A control without a guardrail is a test with no mechanism. You need both. The guardrail does the work. The control proves the work was done.
Next in this series: “Anatomy of an evidence pack,” a walkthrough of what an audit-ready evidence package actually contains for an AI system in production.
Selected References
- Noma Security, “ForcedLeak: AI Agent risks exposed in Salesforce AgentForce,” September 2025. CVSS 9.4 vulnerability chain in Agentforce via indirect prompt injection through Web-to-Lead forms. Reported July 28, patched September 8, disclosed September 25.
- PromptArmor, “Data Exfiltration from Slack AI via indirect prompt injection,” August 2024. Demonstrated private channel data leakage through poisoned public channel messages.
- Gravitee, “State of AI Agent Security 2026.” 81% of agents beyond planning, 14.4% with full security approval.
- EU AI Act, main regime applicable 2 August 2026, certain high-risk obligations phased through August 2027.
- California SB 243, effective January 2026. Companion chatbot disclosure, self-harm intervention, and minor-specific requirements. Excludes customer service, operational, and internal research systems.
- SOC 2 Trust Services Criteria, AICPA. Security, Availability, Processing Integrity, Confidentiality, Privacy.
- ISO/IEC 42001:2023, AI Management System standard.